Streamlit, o framework que deixa a vida dos cientistas de dados mais agradável
Imagine que um cientista de dados recebeu datasets, ele trabalhou muito, padronizando, normalizando e limpando valores inválidos. Agora, ele precisa obter percepções e descobrir se existe algum comportamento. Para fazer isto, ele plota alguns gráficos, calcula médias e outras tarefas repetitivas. Passado algum tempo, ele recebe datasets atualizados e precisa repetir tudo.

Agora, imagine o cientista de dados trabalhando com uma ferramenta, flexível, simples e fácil de disponibilizar em produção, que permite a manipulação de dados para fazer tarefas recorrentes e a mesma foi feita pelo próprio profissional que a usa.

Se este cientista de dados usar o Streamlit, é possível. De acordo com o site, a definição para o Streamlit é:
um framework mínimo para aplicações poderosas.
Ele foi feito para ser usado com Python, criar interfaces bonitas e colocar na web sem se preocupar com as complexidades de desenvolvimento backend.
Minha proposta com este post é criar uma aplicação simples, onde alguém pode fazer uma análise exploratória e ao mesmo tempo mostrar a você o quão simples é o Streamlit. Com esta aplicação, será possível fazer o enviar um arquivo, também exibir algumas estatísticas sobre as linhas e por fim, disponibilizar gráficos (histograma, dispersão e caixa).
Vamos lá!
Primeiramente, nós precisar rodar o Streamlit. Para esta tarefa, eu gosto de usar o Docker, então vamos criar alguns arquivos, são eles: requirements.txt, Dockerfile, docker-compose.yml e o app.py.
requirements.txt
numpy
pandas
matplotlib
streamlit
Dockerfile
FROM python:3.8-slim-buster
MAINTAINER Fernando Mariano <fernando.mar16@gmail.com>
RUN mkdir /app
COPY . /app
RUN pip install --upgrade pip
RUN pip install -r /app/requirements.txt
ENV GIT_PYTHON_REFRESH="quiet"
WORKDIR /app
docker-compose.yml
version: '3.7'
services:
app:
build: .
container_name: streamlit_app
command: streamlit run app.py
volumes:
- .:/app
ports:
- "8501:8501"
app.py
def main():
# Sim!!! O Streamlit permite o uso de markdown :)
st.markdown("# Data exploratory application")
if __name__ == '__main__':
main()
Agora, execute docker-compose up no terminal, espere até terminar de processar, abra o navegador e digite http://localhost:8051. Se os passos anteriores funcionaram, você verá:

O próximo passo será inserir um campo para fazer o upload de um dataset, ler o mesmo e disponibilizar as estatísticas sobre as linhas.
def main():
# Sim!!! O Streamlit permite o uso de markdown :)
st.markdown("# Data exploratory application")
# Campo para enviar apenas arquivos .csv
file = st.file_uploader("Upload a dataset:", type=['csv'])
if file:
# Se o upload funcionou, então é lido e mostrado os dados em um tabela
data = pd.read_csv(file)
st.dataframe(data.head())
# Coloca um subtítulo
st.markdown("## Rows")
# Exibe o total de linhas
st.markdown(f"__Rows__: {len(data)}")
# Campo para selecionar uma coluna
column = st.selectbox("Select the column", data.columns)
# Se uma coluna foi escolhida, algumas estatísticas são apresentadas
if column:
st.markdown(f"__NaN rows__: {data[column].isna().sum()}")
st.markdown(f"__Mean__: {data[column].mean()}")
st.markdown(f"__Median__: {data[column].median()}")
st.markdown(f"__Mode__: {data[column].mode()[0] }")
Depois das alterações, eu enviei o mesmo dataset que eu escrevi sobre neste post para testar.
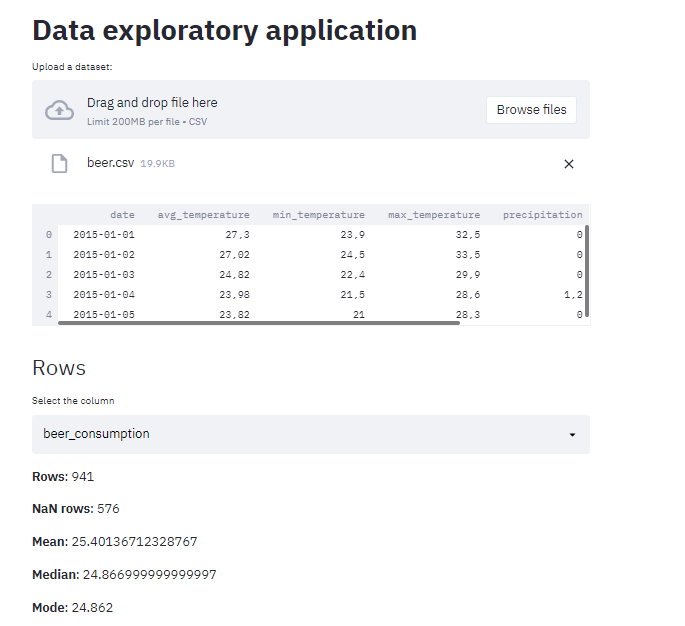
Nosso projetinho está ficando bacana! Agora, vamos colocar os gráficos!
# Coloca um subtítulo
st.markdown("## Charts")
# Opções de gráficos
options = ['Histogram', 'Scatter', 'Box']
chart = st.radio('Choose a chart', options)
# Oculta alguns alertas
st.set_option('deprecation.showPyplotGlobalUse', False)
if chart == 'Histogram':
# se escolher esta opção uma lista de colunas é disponibilizada
column = st.selectbox("Select a column", data.columns)
# Depois de selecionar a coluna o gráfico é exibido
plt.hist(data[column].values)
st.pyplot()
if chart == 'Scatter':
# Como você deve gráficos de dispersão gráficos de dispersão
# são usados para analisar correlação, esse é o motivo
# para exibir opção para selecionar duas colunas
x = st.selectbox("Select the X axis", data.columns)
y = st.selectbox("Select the Y axis", data.columns)
if x and y:
# quando as colunas tiverem valores, os mesmos serão plotados
x = data[x].values
x = x.reshape(-1, 1)
plt.scatter(x, data[y].values)
st.pyplot()
if chart == 'Box':
# Campo para selecionar muitas colunas
columns = st.multiselect("Select the columns", data.columns)
if len(columns) > 0:
# Foi escolhida alguma coluna? Então plote o gráfico
data.boxplot(column=columns)
st.pyplot()
É hora de ver os resultados!
Histograma
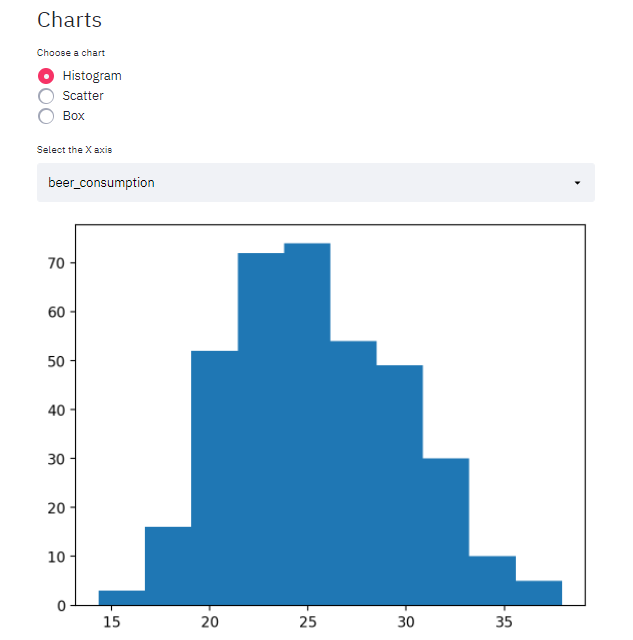
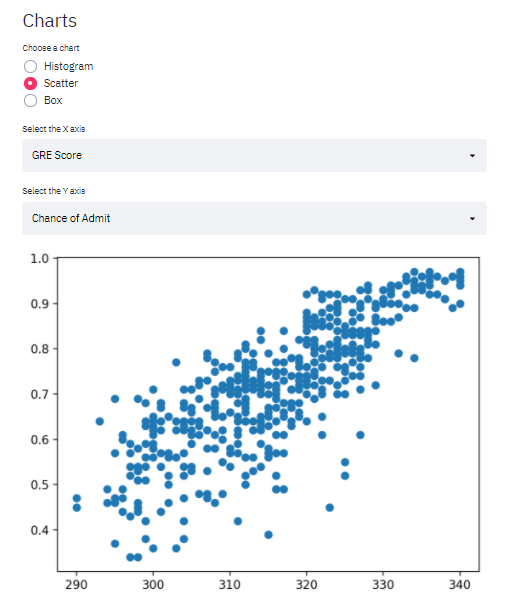
Para exemplificar os gráficos de dispersão e caixa, eu enviei o dataset que eu usei no post sobre Regressão Linear Multipla.
Dispersão
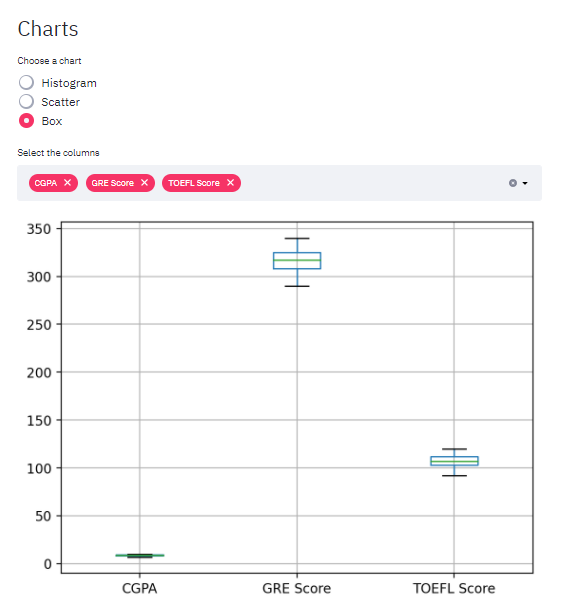
Caixa
Como eu disse no início, meu objetivo com este artigo era mostrar como criar uma aplicação simples que pode ajudar cientistas de dados. Eu não me preocupei com padrões de código usados em Python, apenas fiz. Claro, este exemplo pode ser melhorado, então fique a vontade para comentar o que você gostou ou não.
O código completo do exemplo está aqui.
Streamlit
cientistas de dados
análise exploratória
Python
Discussion and feedback