Média salarial de Alagoas
Este exercício é de um curso da Udemy que eu fiz. No curso, eu precisei fazer uma tabela com valores estatísticos (média, mediana, desvio padrão, etc…). Então eu decidi fazer o mesmo exercício com Python e suas bibliotecas.
O professor do curso providenciou uma planilha com dados do Censo do IBGE de 2010. Foi incluído neste exerício uma amostra com trinta cidades e também definido que seria usado a amostra estratificada por causa das mesorregiões.
O meu primeiro passo foi criar uma nova planilha usando os valores da planilha original para tornar meu trabalho mais fácil, depois exportei para um arquivo CSV e importe usando Pandas.
# Importo o CSV, defino ponto e vírgula como um delimitador e informo que NaN é referente a valores nulos
data = pd.read_csv("CidadesAlagoas.csv", delimiter=';', keep_default_na=False, na_values=['NaN'])
# Definido número da amostra
NUM_SAMPLE = 30
# Os filtros da cidade por mesorregião
filter_agreste = data[data['mesoregion'] == 'Agreste Alagoano']
filter_sertao = data[data['mesoregion'] == 'Sertão Alagoano']
filter_leste = data[data['mesoregion'] == 'Leste Alagoano']
Cada mesorregião tem um número de cidades que precisam ser sorteads e separadas proporcionamente. Para escolher as cidades, Eu contei o total de cidades por mesorregião.
number_cities_agreste = len(filter_agreste)
number_cities_sertao = len(filter_sertao)
number_cities_leste = len(filter_leste)
number_cities = len(data)
print ('''
Número de cidades do Agreste Alagoano: %d
Número de cidades do Sertão Alagoano: %d
Número de cidades do Leste Alagoano: %d
''' %(number_cities_agreste, number_cities_sertao, number_cities_leste))
#-------------------OUT-------------------#
# Número de cidades do Agreste Alagoano: 24
# Número de cidades do Sertão Alagoano: 26
# Número de cidades do Leste Alagoano: 52
#-------------------OUT-------------------#
Depois disto, eu calculei o peso para cada mesorregião divindo o total de cidades de cada mesorregião pelo total de cidades do estado.
weight_agreste = float(number_cities_agreste)/number_cities
weight_sertao = float(number_cities_sertao)/number_cities
weight_leste = float(number_cities_leste)/number_cities
print ('''
Peso do Agreste Alagoano: %.2f
Peso do Sertão Alagoano: %.2f
Peso do Leste Alagoano: %.2f
''' %(weight_agreste, weight_sertao, weight_leste))
#-----------------OUT---------------#
# Peso do Agreste Alagoano: 0.24
# Peso do Sertão Alagoano: 0.25
# Peso do Leste Alagoano: 0.51
#-----------------OUT---------------#
And then I got the sure quantity cities by mesoregion making a multiplication with weight and total samples.
number_draw_cities_agreste = int(round(weight_agreste * NUM_SAMPLE))
number_draw_cities_sertao = int(round(weight_sertao * NUM_SAMPLE))
number_draw_cities_leste = int(round(weight_leste * NUM_SAMPLE))
print ('''
Número de cidades para sortear in Agreste Alagoano: %.d
Número de cidades para sortear in Sertão Alagoano: %.d
Número de cidades para sortear in Leste Alagoano: %.d
''' %(number_draw_cities_agreste, number_draw_cities_sertao, number_draw_cities_leste))
#-------------------------OUT------------------------------#
# Número de cidades para sortear no Agreste Alagoano: 7
# Número de cidades para sortear no Sertão Alagoano: 8
# Número de cidades para sortear no Leste Alagoano: 15
#-------------------------OUT------------------------------#
Com o número de cidades, eu as sortei assim.
# O primeiro parametro é a quantiade e eu defino 'replace' como falso para não repetir
draw_agreste = filter_agreste.sample(n=number_draw_cities_agreste, replace=False)
draw_sertao = filter_sertao.sample(n=number_draw_cities_sertao, replace=False)
draw_leste = filter_leste.sample(n=number_draw_cities_leste, replace=False)
# Criei um DataFrame para cada mesorregião
agreste = pd.DataFrame(draw_agreste)
sertao = pd.DataFrame(draw_sertao)
leste = pd.DataFrame(draw_leste)
# Juntei todas as mesorregiões
new_data = pd.concat([agreste, sertao, leste])
# Então aqui eu mostrao o DataFrame
new_data
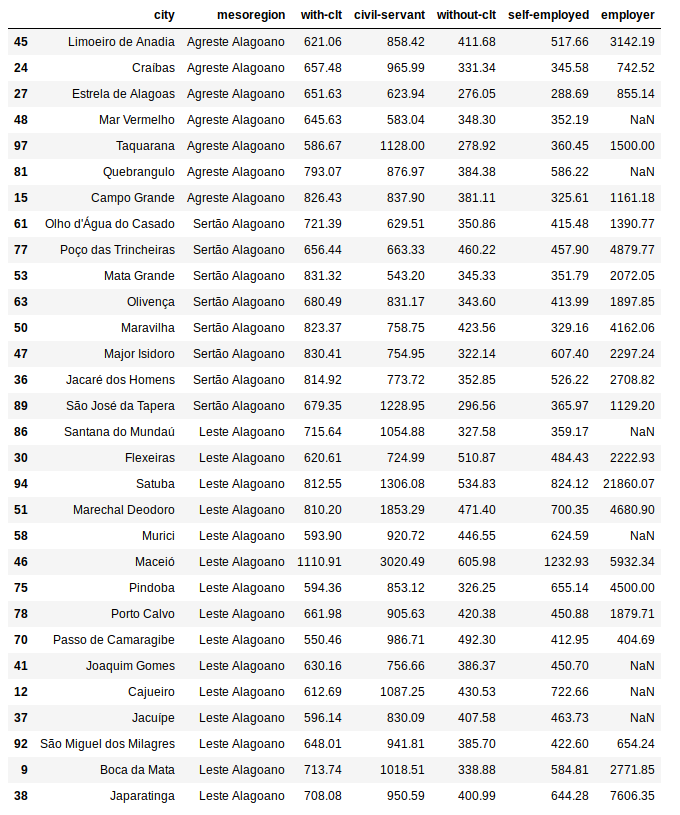
Com as cidades sorteadas, precisei obter os valores pedidos (média, mediana, desvio padrão, coeficiente de variação, menor valor, maior valor, quartil de 25%, quartil de 75%, percentil de 10% e percentil de 90%).
# A função describe algum dos valores por padrão
describe = new_data.describe()
# Criei um dicionário para organizar os valores por cargo
result = {
'with-clt': {
'mean': describe['with-clt']['mean'],
'median': new_data['with-clt'].median(),
'cv': (describe['with-clt']['std']/describe['with-clt']['mean'])*100,
'sd': describe['with-clt']['std'],
'min': describe['with-clt']['min'],
'max': describe['with-clt']['max'],
'q1': describe['with-clt']['25%'],
'q3': describe['with-clt']['75%'],
'p10': new_data['with-clt'].quantile(.10),
'p90': new_data['with-clt'].quantile(.90)
},
'civil-servant': {
'mean': describe['civil-servant']['mean'],
'median': new_data['civil-servant'].median(),
'cv': (describe['civil-servant']['std']/describe['civil-servant']['mean'])*100,
'sd': describe['civil-servant']['std'],
'min': describe['civil-servant']['min'],
'max': describe['civil-servant']['max'],
'q1': describe['civil-servant']['25%'],
'q3': describe['civil-servant']['75%'],
'p10': new_data['civil-servant'].quantile(.10),
'p90': new_data['civil-servant'].quantile(.90)
},
'without-clt': {
'mean': describe['without-clt']['mean'],
'median': new_data['without-clt'].median(),
'cv': (describe['without-clt']['std']/describe['without-clt']['mean'])*100,
'sd': describe['without-clt']['std'],
'min': describe['without-clt']['min'],
'max': describe['without-clt']['max'],
'q1': describe['without-clt']['25%'],
'q3': describe['without-clt']['75%'],
'p10': new_data['without-clt'].quantile(.10),
'p90': new_data['without-clt'].quantile(.90)
},
'self-employed': {
'mean': describe['self-employed']['mean'],
'median': new_data['self-employed'].median(),
'cv': (describe['self-employed']['std']/describe['self-employed']['mean'])*100,
'sd': describe['self-employed']['std'],
'min': describe['self-employed']['min'],
'max': describe['self-employed']['max'],
'q1': describe['self-employed']['25%'],
'q3': describe['self-employed']['75%'],
'p10': new_data['self-employed'].quantile(.10),
'p90': new_data['self-employed'].quantile(.90)
},
'employer': {
'mean': describe['employer']['mean'],
'median': new_data['employer'].median(),
'cv': (describe['employer']['std']/describe['employer']['mean'])*100,
'sd': describe['employer']['std'],
'min': describe['employer']['min'],
'max': describe['employer']['max'],
'q1': describe['employer']['25%'],
'q3': describe['employer']['75%'],
'p10': new_data['employer'].quantile(.10),
'p90': new_data['employer'].quantile(.90)
}
}
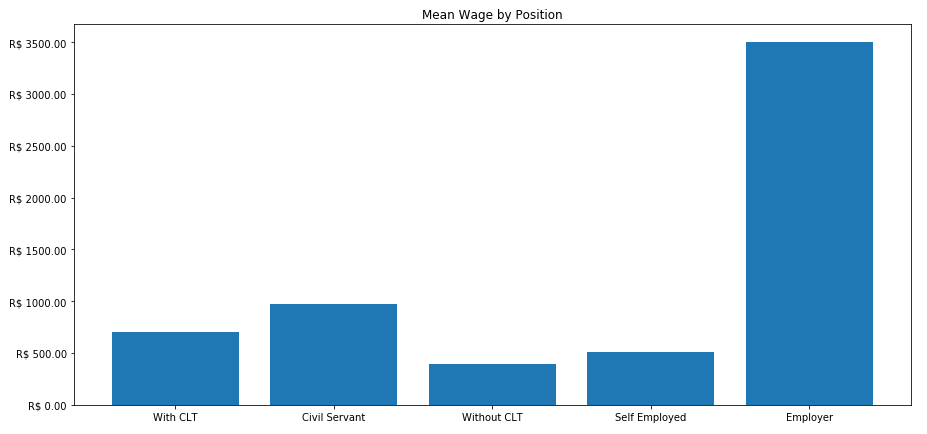
Para finalizar o exercício, fiz um gráfico com as médias por cargo.
Considerações
Este foi um outro exercócio que eu fiz para melhorar minhas habilidades. Se você tem alguma dúvida ou sugestão seu comentário é bem vindo :)
data science
python
statistic
Discussion and feedback