Meu primeiro projeto em Data Science
Nesse post pretendo descrever meu primeiro projeto de Ciência de Dados. O projeto consiste em estudar os dados da Trimania que são disponibilizados no site da instituição. Nele eu levantei informações bem simples, como: números sorteados e bairros que mais tiveram ganhadores em um período.
Como obtive os dados
Para obter os dados eu criei um crawler. O mesmo foi desenvolvido em PHP utilizando uma biblioteca do framework Symfony. As informações recebidas são salvas em duas tabelas: uma para localização e outra para os números.
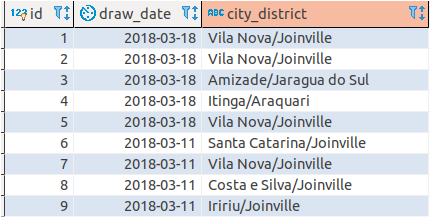
Uma das dificuldades para executar esse projeto é o tratamento de dados. Sempre que importado um conjunto de dados foi necessário realizar o tratamento deles, pois, constantemente o nome das cidades divergiam. Como exemplo em sorteios que existem ganhadores na cidade Joinville. No site os dados eram apresentados da seguinte forma: “Bairro / Joinvillle”, “Joinvile/Bairro”, “Joinville /Bairro”. Abaixo alguns exemplos do problema citado no sorteio do dia 02/09/2018.

Não realizando a correção desses dados a análise seria errônea. Na imagem seguinte é mostrada alguns bairros juntamente com a cidade após ter sido feita a correção dos caracteres.
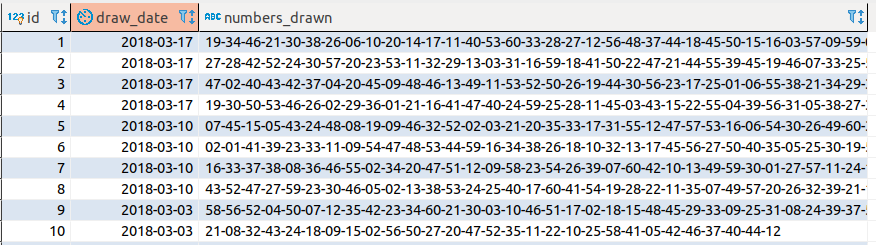
Os números sorteados não tem uma quantidade exata como na Mega-Sena, ou seja, a quantidade de números sorteados por rodada vai variar. Logo, não optei por ter uma coluna para cada valor sorteado. Criei uma coluna do tipo texto e salvei usando hífen como separador.
Análise dos números
Como este projeto é para estudos eu criei uma pergunta que eu gostaria de responder, a pergunta que elaborei foi ‘Quais os números mais sorteados de Janeiro a Abril de 2018?’. Para conseguir a resposta comecei exportando um CSV e depois utilizei o Jupyter Notebook para analisar.
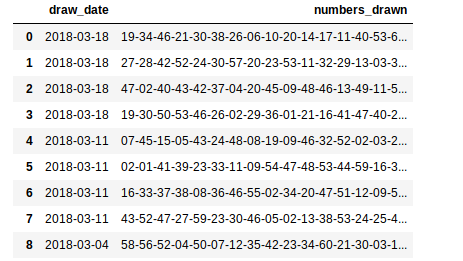
# Nesta linha eu faço a leitura do arquivo e mostro uma prévia do que foi importado.
csv = pd.read_csv('trimaniaNumbers.csv', delimiter=';');
csv
# Dicionário para inserir os números
numbers = {
'number':[]
}
# Separando os números por hífen e acrescentado os números no dicionário
for lines in csv['numbers_drawn']:
for number in lines.split('-'):
numbers['number'].append(number)
# Utilizei o dicionado para gerar um novo DataFrame
df = pd.DataFrame(numbers)
# Conto os números repetidos e solicito os 20 primeiros
data = df['number'].value_counts().head(20)
Para visualizar de maneira mais amigável, gerei um gráfico de Números X Quantidade.
# Configuro a fonte
font = {
'weight': 'normal',
'size': 16
}
# Configuro a label dos eixos X e Y
plt.xlabel('Numbers', fontdict=font)
plt.ylabel('Quantity', fontdict=font)
# Exibo um gráfico em barra
data.plot(kind='bar')
plt.show()
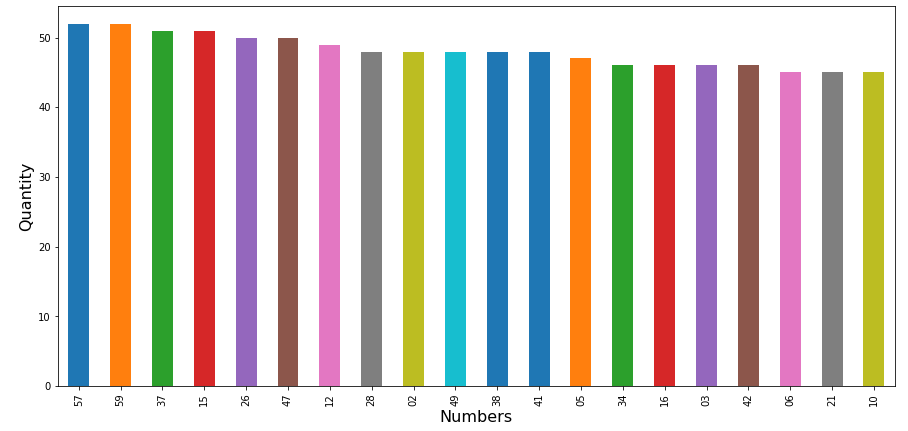
Análise das localizações
No estudo das localizações também elaborei uma pergunta: ‘Quais os bairros que mais tiveram ganhadores entre Janeiro e Abril de 2018 na cidade de Joinville?’. Para conseguir a resposta para tal pergunta fiz apenas uma SQL simples.
SELECT COUNT(*) AS total, city_district
FROM locations
WHERE draw_date BETWEEN '2018-01-01' AND '2018-04-30'
AND city_district like '%/Joinville%'
GROUP BY city_district
ORDER BY total DESC
Após executar a SQL acima eu obtive a minha resposta:
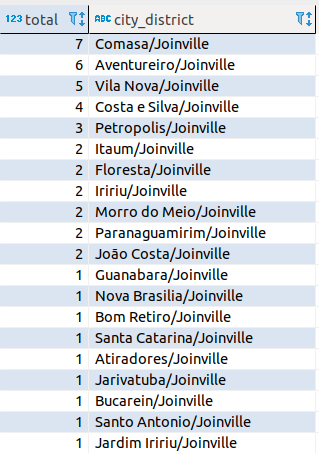
Considerações
Este projeto não possui muitas complexidades. Ainda preciso melhorar meus conhecimentos construindo desafios mais complexos. Mesmo assim acredito que este exerício tem um grande valor. Se você tiver alguma dúvida ou sugestão, fique a vontade para comentar :)
data science
python
Discussion and feedback